Anagram是一个比较流行的英文文字游戏,本Blog之前曾经介绍过,这里我再提一下。Anagram就是把一个词或者一句话里的字母重新排列,组成一个新的单词或句子,通常前后两者有一种讽刺的意味。比如,Dormitory = Dirty Room,或者Desperation = A Rope Ends It。创作一个有意思的Anagram并不是一件容易的事,你很可能需要计算机的帮助才能找到合适的词。例如,我们可以利用Hash表瞬间找出与给定单词所使用的字母完全相同的单词。我们可以把字典中每个单词的字母按照字母顺序重新排列,于是对单词dame和made操作后的结果都是adem,这样的话使用字母完全相同的单词就对应了一个唯一的Hash值,我们就可以方便地把它们归在一起。
而实际上,这个Hash表往往没什么用。一个Anagram很可能是由多个单词构成的,因此我们更希望知道,使用某个单词中的字母(不一定全部使用)可以构造出哪些新的单词。例如,我输入单词dormitory,则程序可以输出dirty, motor, trim, dry, room等单词。很多Anagram辅助程序都有这样的功能,并且这也单独作为一个文字游戏存在。我们称这种只用到一部分给定字母的单词叫做不完全Anagram。假如字典里共有n个单词,输入数据长度为l,那么你怎样才能找出所有的不完全Anagram?一种方法是遍历所有n个单词,依次判断每个单词是否合法;另一种方法则是枚举输入数据的2^l子集,对每个子集在之前建立的Hash表中查询一次。现在,你能否想出一个数据结构,使得你的Anagram辅助程序能够以最快的速度输出任何一个给定单词的不完全Anagram?
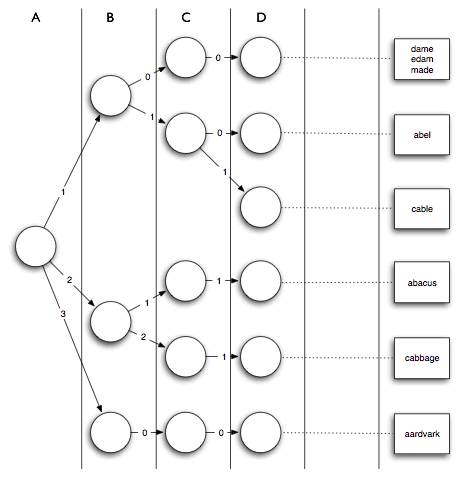
答案比你想像的更简单,这是一个非常简单的数据结构。我们建立一棵高度为26的树,按照每个字母出现的次数像Trie一样插入到树中。比如,abacus有2个a,于是插入到根的第二个子树里,接下来数出字母b的个数为1,并继续沿标号为1的边往下走,依此类推。最后,所有的数据都存放在对应的叶子节点上。查询时,在每个节点上只需数一数输入数据中对应字母的个数N,沿着标号小于等于N的边往下走就行了。
下面是一个非常有趣的问题:这个数据结构还有什么优化的余地?比如,单词在树中是按照从A到Z的顺序依次分类,但实际上我们可以任意调整这个顺序。那么,你觉得建这棵树时是先按E、T等常用字母的个数分类好,还是先按照Q、Z等不常用字母的个数分类好?这个问题很简单,留给大家思考吧。
另一个比较类似的东西是用于拼写检查的数据结构。这两个有趣的数据结构都是我在这里看到的。
做人要厚道
转贴请注明出处