Hash表是一个很有用的数据结构,它用O(N)的空间描述一个元素在0到N-1范围内的集合,支持常数级别的添加、删除和查询。遗憾的是,Hash表不能在常数时间内批量删除元素,返回全部元素也需要O(N)的时间,而理论上说这几个操作可以做的更好。现在,你能否设计一个数据结构,它同样占用O(N)的空间,支持常数时间的添加、删除、查询、清空(删除所有元素)、势查询(返回元素个数),以及O(n)时间的元素遍历(其中n表示集合中的元素个数)。
数据结构
趣题:Anagram辅助程序的数据结构
Anagram是一个比较流行的英文文字游戏,本Blog之前曾经介绍过,这里我再提一下。Anagram就是把一个词或者一句话里的字母重新排列,组成一个新的单词或句子,通常前后两者有一种讽刺的意味。比如,Dormitory = Dirty Room,或者Desperation = A Rope Ends It。创作一个有意思的Anagram并不是一件容易的事,你很可能需要计算机的帮助才能找到合适的词。例如,我们可以利用Hash表瞬间找出与给定单词所使用的字母完全相同的单词。我们可以把字典中每个单词的字母按照字母顺序重新排列,于是对单词dame和made操作后的结果都是adem,这样的话使用字母完全相同的单词就对应了一个唯一的Hash值,我们就可以方便地把它们归在一起。
而实际上,这个Hash表往往没什么用。一个Anagram很可能是由多个单词构成的,因此我们更希望知道,使用某个单词中的字母(不一定全部使用)可以构造出哪些新的单词。例如,我输入单词dormitory,则程序可以输出dirty, motor, trim, dry, room等单词。很多Anagram辅助程序都有这样的功能,并且这也单独作为一个文字游戏存在。我们称这种只用到一部分给定字母的单词叫做不完全Anagram。假如字典里共有n个单词,输入数据长度为l,那么你怎样才能找出所有的不完全Anagram?一种方法是遍历所有n个单词,依次判断每个单词是否合法;另一种方法则是枚举输入数据的2^l子集,对每个子集在之前建立的Hash表中查询一次。现在,你能否想出一个数据结构,使得你的Anagram辅助程序能够以最快的速度输出任何一个给定单词的不完全Anagram?
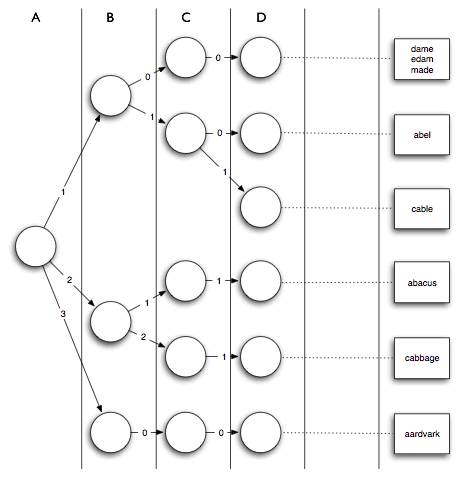
答案比你想像的更简单,这是一个非常简单的数据结构。我们建立一棵高度为26的树,按照每个字母出现的次数像Trie一样插入到树中。比如,abacus有2个a,于是插入到根的第二个子树里,接下来数出字母b的个数为1,并继续沿标号为1的边往下走,依此类推。最后,所有的数据都存放在对应的叶子节点上。查询时,在每个节点上只需数一数输入数据中对应字母的个数N,沿着标号小于等于N的边往下走就行了。
下面是一个非常有趣的问题:这个数据结构还有什么优化的余地?比如,单词在树中是按照从A到Z的顺序依次分类,但实际上我们可以任意调整这个顺序。那么,你觉得建这棵树时是先按E、T等常用字母的个数分类好,还是先按照Q、Z等不常用字母的个数分类好?这个问题很简单,留给大家思考吧。
另一个比较类似的东西是用于拼写检查的数据结构。这两个有趣的数据结构都是我在这里看到的。
做人要厚道
转贴请注明出处
编辑距离、拼写检查与度量空间:一个有趣的数据结构
除了字符串匹配、查找回文串、查找重复子串等经典问题以外,日常生活中我们还会遇到其它一些怪异的字符串问题。比如,有时我们需要知道给定的两个字符串“有多像”,换句话说两个字符串的相似度是多少。1965年,俄国科学家Vladimir Levenshtein给字符串相似度做出了一个明确的定义叫做Levenshtein距离,我们通常叫它“编辑距离”。字符串A到B的编辑距离是指,只用插入、删除和替换三种操作,最少需要多少步可以把A变成B。例如,从FAME到GATE需要两步(两次替换),从GAME到ACM则需要三步(删除G和E再添加C)。Levenshtein给出了编辑距离的一般求法,就是大家都非常熟悉的经典动态规划问题。
在自然语言处理中,这个概念非常重要,例如我们可以根据这个定义开发出一套半自动的校对系统:查找出一篇文章里所有不在字典里的单词,然后对于每个单词,列出字典里与它的Levenshtein距离小于某个数n的单词,让用户选择正确的那一个。n通常取到2或者3,或者更好地,取该单词长度的1/4等等。这个想法倒不错,但算法的效率成了新的难题:查字典好办,建一个Trie树即可;但怎样才能快速在字典里找出最相近的单词呢?这个问题难就难在,Levenshtein的定义可以是单词任意位置上的操作,似乎不遍历字典是不可能完成的。现在很多软件都有拼写检查的功能,提出更正建议的速度是很快的。它们到底是怎么做的呢?1973年,Burkhard和Keller提出的BK树有效地解决了这个问题。这个数据结构强就强在,它初步解决了一个看似不可能的问题,而其原理非常简单。
首先,我们观察Levenshtein距离的性质。令d(x,y)表示字符串x到y的Levenshtein距离,那么显然:
1. d(x,y) = 0 当且仅当 x=y (Levenshtein距离为0 <==> 字符串相等)
2. d(x,y) = d(y,x) (从x变到y的最少步数就是从y变到x的最少步数)
3. d(x,y) + d(y,z) >= d(x,z) (从x变到z所需的步数不会超过x先变成y再变成z的步数)
最后这一个性质叫做三角形不等式。就好像一个三角形一样,两边之和必然大于第三边。给某个集合内的元素定义一个二元的“距离函数”,如果这个距离函数同时满足上面说的三个性质,我们就称它为“度量空间”。我们的三维空间就是一个典型的度量空间,它的距离函数就是点对的直线距离。度量空间还有很多,比如Manhattan距离,图论中的最短路,当然还有这里提到的Levenshtein距离。就好像并查集对所有等价关系都适用一样,BK树可以用于任何一个度量空间。
建树的过程有些类似于Trie。首先我们随便找一个单词作为根(比如GAME)。以后插入一个单词时首先计算单词与根的Levenshtein距离:如果这个距离值是该节点处头一次出现,建立一个新的儿子节点;否则沿着对应的边递归下去。例如,我们插入单词FAME,它与GAME的距离为1,于是新建一个儿子,连一条标号为1的边;下一次插入GAIN,算得它与GAME的距离为2,于是放在编号为2的边下。再下次我们插入GATE,它与GAME距离为1,于是沿着那条编号为1的边下去,递归地插入到FAME所在子树;GATE与FAME的距离为2,于是把GATE放在FAME节点下,边的编号为2。
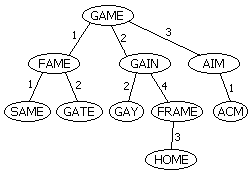
查询操作异常方便。如果我们需要返回与错误单词距离不超过n的单词,这个错误单词与树根所对应的单词距离为d,那么接下来我们只需要递归地考虑编号在d-n到d+n范围内的边所连接的子树。由于n通常很小,因此每次与某个节点进行比较时都可以排除很多子树。
举个例子,假如我们输入一个GAIE,程序发现它不在字典中。现在,我们想返回字典中所有与GAIE距离为1的单词。我们首先将GAIE与树根进行比较,得到的距离d=1。由于Levenshtein距离满足三角形不等式,因此现在所有离GAME距离超过2的单词全部可以排除了。比如,以AIM为根的子树到GAME的距离都是3,而GAME和GAIE之间的距离是1,那么AIM及其子树到GAIE的距离至少都是2。于是,现在程序只需要沿着标号范围在1-1到1+1里的边继续走下去。我们继续计算GAIE和FAME的距离,发现它为2,于是继续沿标号在1和3之间的边前进。遍历结束后回到GAME的第二个节点,发现GAIE和GAIN距离为1,输出GAIN并继续沿编号为1或2的边递归下去(那条编号为4的边连接的子树又被排除掉了)……
实践表明,一次查询所遍历的节点不会超过所有节点的5%到8%,两次查询则一般不会17-25%,效率远远超过暴力枚举。适当进行缓存,减小Levenshtein距离常数n可以使算法效率更高。
Matrix67原创
做人要厚道 转贴请注明出处
Google面试题中的两道趣题
看看下面两道题,它的解答非常简单,即使没学过信息学的人也可以想到答案。你能在多短的时间内想出问题的算法来?一小时?一分钟?一秒钟?
1. 给你一个长度为N的链表。N很大,但你不知道N有多大。你的任务是从这N个元素中随机取出k个元素。你只能遍历这个链表一次。你的算法必须保证取出的元素恰好有k个,且它们是完全随机的(出现概率均等)。
2. 给你一个数组A[1..n],请你在O(n)的时间里构造一个新的数组B[1..n],使得B[i]=A[1]*A[2]*…*A[n]/A[i]。你不能使用除法运算。
Solution:
1. 遍历链表,给每个元素赋一个0到1之间的随机数作为权重(像Treap一样),最后取出权重最大的k个元素。你可以用一个堆来维护当前最大的k个数。
2. 从前往后扫一遍,然后从后往前再扫一遍。也就是说,线性时间构造两个新数组,P[i]=A[1]*A[2]*…*A[i],Q[i]=A[n]*A[n-1]*…*A[i]。于是,B[i]=P[i-1]*Q[i+1]。
突然想到,给别人(MM?)介绍信息学时,用这两道题当例子挺合适的。
分享三道题目的代码+JavaScript Syntax Highlight测试
寒假时没事写了这几个代码,算是我几个月后重操键盘了。这是几道经典题目,可能有人需要,再加上昨天搞JavaScript改过去改过来把PJBlog改得面目全非终于实现了代码高亮忍不住想Show一下,于是把这些代码(连同题目)发了上来。
标准的网络流题目代码
Problem : goods
货物运输问题描述
你第一天接手一个大型商业公司就发生了一件倒霉的事情:公司不小心发送了一批次品。很不幸,你发现这件事的时候,这些次品已经进入了送货网。这个送货网很大,而且关系复杂。你知道这批次品要发给哪个零售商,但是要把这批次品送到他手中有许多种途径。送货网由一些仓库和运输卡车组成,每辆卡车都在各自固定的两个仓库之间单向运输货物。在追查这些次品的时候,有必要保证它不被送到零售商手里,所以必须使某些运输卡车停止运输,但是停止每辆卡车都会有一定的经济损失。你的任务是,在保证次品无法送到零售商的前提下,制定出停止卡车运输的方案,使损失最小。输入格式
第一行:两个用空格分开的整数N(0<=N<=200)和M(2<=M<=200)。N为运输卡车的数目,M为仓库的数目。1号仓库是公司发货的出口,仓库M属于零售商。
第二行到第N+1行:每行有三个整数,Si、Ei和Ci。Si和Ei(1<=Si,Ei<=M)分别表示这辆卡车的出发仓库和目的仓库,Ci(0<=Ci<=10,000,000)是让这辆卡车停止运输的损失。输出格式
输出一个整数,即最小的损失数。样例输入
5 4
1 2 40
1 4 20
2 4 20
2 3 30
3 4 10样例输出
50样例说明
40
1——>2
| /|
| / |
20| / |30
| 20 |
| / |
| / |
/_ V
4<——3
10如图,停止1->4、2->4、3->4三条卡车运输线路可以阻止货物从仓库1运输到仓库4,代价为20+20+10=50。
数据规模
对于50%的数据,N,M<=25
对于100%的数据,N,M<=200
program goods;
const
MaxN=200;
MaxM=200;
Infinite=Maxlongint;
type
rec=record
node,father:integer;
minf:longint;
end;
var
f,c:array[1..MaxN,1..MaxN]of longint;
queue:array[1..MaxN]of rec;
hash:array[1..MaxN]of boolean;
n,m,closed,open:integer;
procedure readp;
var
i,x,y:integer;
t:longint;
begin
readln(m,n);
for i:=1 to m do
begin
readln(x,y,t);
c[x,y]:=c[x,y]+t;
end;
end;
function FindPath:boolean;
procedure Init;
begin
fillchar(hash,sizeof(hash),0);
fillchar(queue,sizeof(queue),0);
closed:=0;
open:=1;
queue[1].node:=1;
queue[1].father:=0;
queue[1].minf:=Infinite;
hash[1]:=true;
end;
function min(a,b:longint):longint;
begin
if a<b then min:=a
else min:=b;
end;
var
i,NodeNow:integer;
begin
Init;
repeat
inc(closed);
NodeNow:=queue[closed].node;
for i:=1 to n do if not hash[i] then
if (f[NodeNow,i]<c[NodeNow,i]) then
begin
inc(open);
queue[open].node:=i;
queue[open].father:=closed;
queue[open].minf:=min(queue[closed].minf,c[NodeNow,i]-f[NodeNow,i]);
hash[i]:=true;
if i=n then exit(true);
end;
until closed>=open;
exit(false);
end;
procedure AddPath;
var
i,j:integer;
delta:longint;
begin
delta:=queue[open].minf;
i:=open;
repeat
j:=queue[i].father;
inc(f[queue[j].node,queue[i].node],delta);
dec(f[queue[i].node,queue[j].node],delta);
i:=j;
until i=0;
end;
procedure writep;
var
i:integer;
ans:longint=0;
begin
for i:=1 to n do
ans:=ans+f[1,i];
writeln(ans);
end;
{====main====}
begin
assign(input,'goods.in');
reset(input);
readp;
close(input);
while FindPath do AddPath;
assign(output,'goods.out');
rewrite(output);
writep;
close(output);
end.
统计逆序对 Treap版
Problem : inverse
逆序对问题描述
在一个排列中,前面出现的某个数比它后面的某个数大,即当Ai>Aj且i<j时,则我们称Ai和Aj为一个逆序对。给出一个1到N的排列,编程求出逆序对的个数。输入格式
第一行输入一个正整数N;
第二行有N个用空格隔开的正整数,这是一个1到N的排列。输出格式
输出输入数据中逆序对的个数。样例输入
4
3 1 4 2样例输出
3样例说明
在输入数据中,(3,1)、(3,2)和(4,2)是仅有的三个逆序对。数据规模
对于30%的数据,N<=1000;
对于100%的数据,N<=100 000。program inverse;const
MaxH=Maxlongint;
type
p=^rec;
rec=record
v,s,h:longint;
left,right:p;
end;var
header:p=nil;
ans:int64=0;procedure CalcuS(var w:p);
begin
w^.s:=1;
if w^.right<>nil then inc(w^.s,w^.right^.s);
if w^.left<>nil then inc(w^.s,w^.left^.s);
end;function RotateLeft(w:p):p;
var
tmp:p;
begin
tmp:=w^.left;
w^.left:=tmp^.right;
tmp^.right:=w;
exit(tmp);
end;function RotateRight(w:p):p;
var
tmp:p;
begin
tmp:=w^.right;
w^.right:=tmp^.left;
tmp^.left:=w;
exit(tmp);
end;function Insert(a:longint;w:p):p;
begin
if w=nil then
begin
new(w);
w^.v:=a;
w^.h:=random(MaxH);
w^.s:=1;
w^.left:=nil;
w^.right:=nil;
endelse if a<w^.v then
begin
ans:=ans+1;
if w^.right<>nil then ans:=ans+w^.right^.s;
w^.left:=Insert(a,w^.left);
if w^.left^.h<w^.h then
begin
w:=RotateLeft(w);
CalcuS(w^.right);
end else
CalcuS(w^.left);
endelse if a>w^.v then
begin
w^.right:=Insert(a,w^.right);
if w^.right^.h<w^.h then
begin
w:=RotateRight(w);
CalcuS(w^.left);
end else
CalcuS(w^.right);
end;exit(w);
end;{====main====}
var
n,i,t:longint;
begin
randseed:=2910238;
assign(input,'inverse.in');
reset(input);
readln(n);
for i:=1 to n do
begin
read(t);
header:=Insert(t,header);
end;
close(input);assign(output,'inverse.out');
rewrite(output);
writeln(ans);
close(output);
end.USACO经典题目:矩形颜色(离散化+扫描)
Problem : rect
矩形颜色问题描述
N个不同颜色的不透明长方形(1<=N<=1000)被放置在一张宽为A长为B的白纸上。这些长方形被放置时,保证了它们的边与白纸的边缘平行。所有的长方形都放置在白纸内,所以我们会看到不同形状的各种颜色。坐标系统的原点(0,0)设在这张白纸的左下角,而坐标轴则平行于边缘。输入数据
每行输入的是放置长方形的方法。第一行输入的是那个放在最底下的长方形(即白纸)。
第一行:A、B和N,由空格分开(1<=A,B<=10,000)
第二到N+1行:每行为五个整数llx,lly,urx,ury,color。这是一个长方形的左下角坐标,右上角坐标和颜色。颜色1和底部白纸的颜色相同。输出数据
输出文件应该包含一个所有能被看到的颜色连同该颜色的总面积的清单(即使颜色的区域不是连续的),按color的增序顺序。
不要打印出最后不能看到的颜色。样例输入
20 20 3
2 2 18 18 2
0 8 19 19 3
8 0 10 19 4样例输出
1 91
2 84
3 187
4 38数据规模
对于50%的数据,A,B<=300,N<=60;
对于100%的数据,A,B<=10000,N<=1000。
program rect;const
MaxN=1000; { Rect number in the Worst Case }
MaxCol=1000; { Color number in the Worst Case }
Infinity=Maxint; { Set to be Heap[0] }type
RecSeg=record
y,x1,x2,order:integer;
end;
var
xar,heap:array[0..MaxN*2+2]of integer; { Array of All X-Value and Heap, respectively }
color:array[1..MaxN+1]of integer; { Index of Color corresponding to order}
ans:array[1..MaxCol]of longint; { Answers to be print }
seg:array[0..MaxN*2+2]of RecSeg; { Horizontal Segments }
hash:array[1..MaxN*2+2]of boolean; { Determine if a Segment has been scanned }
n,HeapSize:integer;procedure SwapInt(var a,b:integer);
var
tmp:integer;
begin
tmp:=a;
a:=b;
b:=tmp;
end;procedure SwapRec(var a,b:RecSeg);
var
tmp:RecSeg;
begin
tmp:=a;
a:=b;
b:=tmp;
end;procedure DataInsert(start,x1,y1,x2,y2,col,order:integer);
var
tmp:RecSeg;
begin
xar[start]:=x1;
xar[start+1]:=x2;
color[start div 2+1]:=col;tmp.order:=order;
tmp.y:=y1;
tmp.x1:=x1;
tmp.x2:=x2;
seg[start]:=tmp;tmp.y:=y2;
seg[start+1]:=tmp;
end;procedure Readp;
var
a,b,x1,x2,y1,y2,col,i:integer;
begin
readln(a,b,n);
n:=n+1;
DataInsert(1,0,0,a,b,1,1);
for i:=2 to n do
begin
readln(x1,y1,x2,y2,col);
DataInsert(2*i-1,x1,y1,x2,y2,col,i);
end;
end;procedure SortXar;
var
i,j:integer;
begin
for i:=1 to 2*n do
for j:=1 to 2*n-1 do
if xar[j]>xar[j+1] then SwapInt(xar[j],xar[j+1]);
end;procedure SortSeg;
var
i,j:integer;
begin
for i:=1 to 2*n do
for j:=1 to 2*n-1 do
if seg[j].y>seg[j+1].y then SwapRec(seg[j],seg[j+1]);
end;procedure HeapInsert(x:integer);
var
w:integer;
begin
inc(HeapSize);
w:=HeapSize;
while Heap[w shr 1]<x do
begin
Heap[w]:=Heap[w shr 1];
w:=w shr 1;
end;
Heap[w]:=x;
end;procedure HeapDelete;
var
&n
bsp; x:integer;
w:integer=1;
begin
x:=Heap[HeapSize];
dec(HeapSize);
while w shl 1<=HeapSize do
begin
w:=w shl 1;
if (w<>HeapSize) and (Heap[w+1]>Heap[w]) then inc(w);
if Heap[w]>x then Heap[w shr 1]:=Heap[w]
else begin
w:=w shr 1;
break;
end;
end;
Heap[w]:=x;
end;procedure Scan(x1,x2:integer);
var
i:integer;
j:integer=0;
begin
for i:=1 to 2*n do if (seg[i].x1<=x1) and (seg[i].x2>=x2) then
begin
inc(ans[Color[Heap[1]]],(x2-x1)*(seg[i].y-seg[j].y));
hash[seg[i].order]:=not hash[seg[i].order];
if hash[seg[i].order] then HeapInsert(seg[i].order)
else while (HeapSize>0) and not hash[Heap[1]] do HeapDelete;
j:=i;
end;
end;procedure Solve;
var
i:integer;
begin
for i:=1 to 2*n-1 do if xar[i]<xar[i+1] then
begin
fillchar(Heap,Sizeof(Heap),0);
fillchar(hash,Sizeof(hash),0);
HeapSize:=0;
Heap[0]:=Infinity;
Scan(xar[i],xar[i+1]);
end;
end;procedure Writep;
var
i:integer;
begin
for i:=1 to MaxCol do
if ans[i]>0 then writeln(i,' ',ans[i]);
end;{====main====}
begin
assign(input,'rect.in');
reset(input);
assign(output,'rect.out');
rewrite(output);Readp;
SortXar;
SortSeg;
Solve;
Writep;close(input);
close(output);
end.这几天大家发现我改PJBlog改错了什么东西导致Bug的话麻烦帮忙报告一下。事实上很有可能有人发现有Bug但是不能报告,因为我很有可能把验证码系统也搞坏了。
如果这几天大家没有发现问题的话,我把这几天我的PJBlog个性修改方法和心得写出来分享一下(越来越喜欢搞Web Design了)。做人要厚道
转贴请注明出处
(这篇日志没什么技术含量,感觉写上这两句很别扭)