Problem 1: Matrix67的情书(二)
大家都知道,看一个数是否能被2整除只需要看它的个位能否被2整除即可。可是你想过为什么吗?这是因为10能被2整除,因此一个数10a+b能被2整除当且仅当b能被2整除。大家也知道,看一个数能否被3整除只需要看各位数之和是否能被3整除。这又是为什么呢?答案或多或少有些类似:因为10^n-1总能被3整除。2345可以写成2*(999+1) + 3*(99+1) + 4*(9+1) + 5,展开就是2*999+3*99+4*9 + 2+3+4+5。前面带了数字9的项肯定都能被3整除了,于是要看2345能否被3整除就只需要看2+3+4+5能否被3整除了。当然,这种技巧只能在10进制下使用,不过类似的结论可以推广到任意进制。
注意到36是4的整数倍,而ZZZ…ZZ除以7总是得555…55。也就是说,判断一个36进制数能否被4整除只需要看它的个位,而一个36进制数能被7整除当且仅当各位数之和能被7整除。如果一个数同时能被4和7整除,那么这个数就一定能被28整除。于是问题转化为,有多少个连续句子满足各位数字和是7的倍数,同时最后一个数是4的倍数。这样,我们得到了一个O(n)的算法:用P[i]表示前若干个句子除以7的余数为i有多少种情况,扫描整篇文章并不断更新P数组。当某句话的最后一个字能被4整除时,假设以这句话结尾的前缀和除以7余x,则将此时P[x]的值累加到最后的输出结果中(两个前缀的数字和除以7余数相同,则较长的前缀多出来的部分一定整除7)。
上述算法是我出这道题的本意,但比赛后我见到了其它各种各样新奇的算法。比如有人注意到36^n mod 28总是等于8,利用这个性质也可以构造出类似的线性算法来。还有人用动态规划(或者说递推)完美地解决了这个问题。我们用f[i,j]表示以句子i结束,除以28余数为j的文本片段有多少个;处理下一句话时我们需要对每一个不同的j进行一次扫描,把f[i-1,j]加进对应的f[i,j']中。最后输出所有的f[i,0]的总和即可。这个动态规划可以用滚动数组,因此它的空间同前面的算法一样也是常数的。
如果你完全不知道我在说什么,你可以看看和进位制、同余相关的文章。另外,我之前还曾出过一道很类似的题(VOJ1090),你可以对比着看一看。
另外,非常抱歉地告诉大家,这道题的最后一个数据是错的。这个数据的第一个句子是一个空句子(感谢Ai.Freedom的提醒)。很多第一题只得了90分的好同志估计都是由于我的失误造成的,这里再次表示歉意。如果去掉最前面的那个问号,输出应该是19511110。
Problem 2: 送给MM的生日礼物
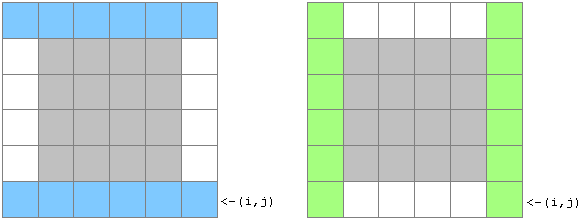
我们用f[i,j,k]表示以第i行第j列的格子为右下角,边长为k的正方形是否符合要求。要想f[i,j,k]=True,首先必须满足f[i-1,j-1,k-2]为True(灰色部分满足要求)。另外,我们还需要保证图中两块蓝色区域相等,两块绿色区域相等,并且这四个区域自身还必须是对称的。由于动态规划的状态已经是三方的了,因此判断后面的这些条件必须在常数时间里完成。为此,我们可以在动态规划前进行以下6个预处理:
以同列不同行的两个格子(i,j)和(i',j)为右端点,同时向左扩展可以得到多长的相等区域
以同行不同列的两个格子(i,j)和(i,j')为最底端,同时向上扩展可以得到多长的相等区域
以格子(i,j)为中心,向左右扩展可以得到多长的对称区域
以格子(i,j)为中心,向上下扩展可以得到多长的对称区域
以两个横向相邻的格子(i,j-1)和(i,j)为中心,向左右扩展可以得到多长的对称区域
以两个纵向相邻的格子(i-1,j)和(i,j)为中心,向上下扩展可以得到多长的对称区域
上面的每个预处理都可以在三方的时间里完成,动态规划的决策降到常数级别,因此总的复杂度还是三方。
同样地,这也只是我出这道题的本意。我事先已经想到,这道题应该还有很多其它的算法,只是没想到会有那么多。一个比较容易想到的算法是,执行与上面相同的预处理后,枚举某个格子(或某个交叉点)为中心,向外一层一层地进行扩展。虽然这样的复杂度仍然是三方的,并且与前面的算法实质相同,但它的效率显然更高,因为你可以在无法再向外扩展时停止最里面的那个循环,继续枚举下一个中心点。
同样是枚举正方形的中心点,只使用上面的后4个预处理也可以解决这个问题。我们可以在线性的时间内找出,以某个格子(或交叉点)为中心的最大的合法正方形。假如这个最大的正方形边长为k,这相当于我们同时找到了(k+1) div 2个正方形来。至于如何找到这个最大的正方形,还是留给大家思考吧。
Cockhorse想到了一个非常巧妙的算法,预处理结束后它可以在常数时间内判断任一个给定的小正方形是否满足题目要求。用f[i,j,k]表示,以第i行中(i,j)及其右边相邻的k-1个格子(共k个格子)来作为底边,所能得到的左右对称的矩形其最大高度是多少。则当f[i,j+1,k-2]为True且(i,j)格与(i,j+k-1)格花色相等时f[i,j,k]=f[i-1,j,k]+1(否则f[i,j,k]=0)。同样地,再用g[i,j,k]表示以(j,i)..(j+k-1,i)作为右边界,使矩形上下对称的最大宽度。这样,判断任意一个正方形是否满足题目要求,只需要检查它的底边和右边能够产生的最大对称区域是否可以覆盖该正方形即可。
当然,这道题目还有很多其它的算法,这里就不一一列举了。
Problem 3: 流言的传播
给定一个图,把图中所有点构成的点集叫做U,另指定一个不等于全集的子集S,那么所有一个顶点在S里另一个顶点在U-S里的边就叫做S点集的“割边”,因为去掉所有这样的边后S集将孤立出来。这道题就是需要你找出一个边集E,使得不管S集是什么,对应的割边中权值最小的那一条一定在边集E中。这样的边集肯定是存在的,比如所有边构成的集合就是一个满足条件的边集。这道题希望你找到的边集E里所含的边尽可能的少。
一个错误的贪心法是,去掉每个点的邻接边中权值最小的那一条。这种算法显然不对,比如下面就是一个鲜活的反例:
o—–o—–o—–o
2 3 1
在上图中,每个点的邻接边中权值最小的不是1就是2,这样的话中间那条边就被保留了下来,于是令S集为左边两个点(或右边两个点),割边仍然一条不少。很容易想到,要想让任意S集的割边中权值最小的被去掉,首先得保证边集E连通了所有的点,否则令S等于任一连通分量,边集E里都不会包含任何一条割边。这样,边集E至少要有n-1条边。
&n
bsp; 考虑到最优解至少是n-1条边,这n-1条边必须连通所有的点,而所选边的权值都应该很小,于是想到最后的答案很可能就是最小生成树。现在假设我们已经选择了某些边,这些边形成了若干个连通分量。考虑所有连接两个不同的连通分量的边(两顶点不在同一连通分量的边)中权值最小的一条,那这条边必须要选,否则令S集为其中一个连通分量,题目条件就不能达到了。这不就是Kruskal算法吗?
且慢,我们还没有证明,对任意一个S集,最小生成树都符合条件。证明其实很简单,假设权值最小的割边e不在最小生成树E中,添加割边e将形成一个回路。这条回路将从S集的某个点出发,经过e跑到U-S里,最后必须还要回到S集。回到S集必然要经过另一条割边e',而显然e'>e(因为e是权值最小的割边,且题目说了没有权值相同的边),于是边集E+{e}-{e'}就成了更小的生成树。
Problem 4: 表白机器人
第四题是整个模拟赛中最简单的题,它不需要你构造任何算法,你只需要按照题目意思进行模拟即可。和去年的NOIp一样,纯粹考编程能力的题目并没有放在第一道题的位置上。这提示大家拿到题目后要先看完所有的题,特别是看到最后一道题时千万别慌,很可能把它的衣服扒光了一看,发现它居然是一道赤裸裸的送分题。
为了加快速度,先预处理出一个数组wall[i][j][k],表示第i行第j列往k(1<=k<=4)方向上走是否走得通。然后枚举所有可能的命令序列,模拟机器人的行走过程,看它是否能到达终点。在模拟过程中,你需要用一个数组hash[i][j][k]表示机器人曾在序列的第k个命令后到达第i行第j列的位置,并在模拟过程中不断更新hash数组;当某一次命令后机器人还没走到右上角,而对应的hash值已经为True了,则机器人的行动将从这里开始循环,永远也到不了右上角了。
虽然这道题不需要任何剪枝,但我还想再说一句。这道题有一个非常有趣的剪枝:命令序列的第一个指令只能是U或R,最后一个指令也只能是U或R。大家想想这是为什么。
