这篇文章是漫话中文分词算法的续篇。在这里,我们将紧接着上一篇文章的内容继续探讨下去:如果计算机可以对一句话进行自动分词,它还能进一步整理句子的结构,甚至理解句子的意思吗?这两篇文章的关系十分紧密,因此,我把前一篇文章改名为了《漫话中文自动分词和语义识别(上)》,这篇文章自然就是它的下篇。我已经在很多不同的地方做过与这个话题有关的演讲了,在这里我想把它们写下来,和更多的人一同分享。
什么叫做句法结构呢?让我们来看一些例子。“白天鹅在水中游”,这句话是有歧义的,它可能指的是“白天有一只鹅在水中游”,也可能指的是“有一只白天鹅在水中游”。不同的分词方案,产生了不同的意义。有没有什么句子,它的分词方案是唯一的,但也会产生不同的意思呢?有。比如“门没有锁”,它可能是指的“门没有被锁上”,也有可能是指的“门上根本就没有挂锁”。这个句子虽然只能切分成“门/没有/锁”,但由于“锁”这个词既有可能是动词,也有可能是名词,因而让整句话产生了不同的意思。有没有什么句子,它的分词方案是唯一的,并且每个词的词义也都不再变化,但整个句子仍然有歧义呢?有可能。看看这句话:“咬死了猎人的狗”。这句话有可能指的是“把猎人的狗咬死了”,也有可能指的是“一只咬死了猎人的狗”。这个歧义是怎么产生的呢?仔细体会两种不同的意思后,你会发现,句子中最底层的成分可以以不同的顺序组合起来,歧义由此产生。
在前一篇文章中,我们看到了,利用概率转移的方法,我们可以有效地给一句话分词。事实上,利用相同的模型,我们也能给每一个词标注词性。更好的做法则是,我们直接把同一个词不同词性的用法当作是不同的词,从而把分词和词性标注的工作统一起来。但是,所有这样的工作都是对句子进行从左至右线性的分析,而句子结构实际上比这要复杂多了,它是这些词有顺序有层次地组合在一起的。计算机要想正确地解析一个句子,在分词和标注词性后,接下来该做的就是分析句法结构的层次。
在计算机中,怎样描述一个句子的句法结构呢? 1957 年, Noam Chomsky 出版了《句法结构》一书,把这种语言的层次化结构用形式化的方式清晰地描述了出来,这也就是所谓的“生成语法”模型。这本书是 20 世纪为数不多的几本真正的著作之一,文字非常简练,思路非常明晰,震撼了包括语言学、计算机理论在内的多个领域。记得 Quora 上曾经有人问 Who are the best minds of the world today ,投出来的答案就是 Noam Chomsky 。
随便取一句很长很复杂的话,比如“汽车被开车的师傅修好了”,我们总能自顶向下地一层层分析出它的结构。这个句子最顶层的结构就是“汽车修好了”。汽车怎么修好了呢?汽车被师傅修好了。汽车被什么样的师傅修好了呢?哦,汽车被开车的师傅修好了。当然,我们还可以无限地扩展下去,继续把句子中的每一个最底层的成分替换成更详细更复杂的描述,就好像小学语文中的扩句练习那样。这就是生成语法的核心思想。
熟悉编译原理的朋友们可能知道“上下文无关文法”。其实,上面提到的扩展规则本质上就是一种上下文无关文法。例如,一个句子可以是“什么怎么样”的形式,我们就把这条规则记作
句子 → 名词性短语+动词性短语
其中,“名词性短语”指的是一个具有名词功能的成分,它有可能就是一个名词,也有可能还有它自己的内部结构。例如,它有可能是一个形容词性短语加上“的”再加上另一个名词性短语构成的,比如“便宜的汽车”;它还有可能是由“动词性短语+的+名词性短语”构成的,比如“抛锚了的汽车”;它甚至可能是由“名词性短语+的+名词性短语”构成的,比如“老师的汽车”。我们把名词性短语的生成规则也都记下来:
名词性短语 → 名词
名词性短语 → 形容词性短语+的+名词性短语
名词性短语 → 动词性短语+的+名词性短语
名词性短语 → 名词性短语+的+名词性短语
⋯⋯
类似地,动词性短语也有诸多具体的形式:
动词性短语 → 动词
动词性短语 → 动词性短语+了
动词性短语 → 介词短语+动词性短语
⋯⋯
上面我们涉及到了介词短语,它也有自己的生成规则:
介词短语 → 介词+名词性短语
⋯⋯
我们构造句子的任务,也就是从“句子”这个初始结点出发,不断调用规则,产生越来越复杂的句型框架,然后从词库中选择相应词性的单词,填进这个框架里:
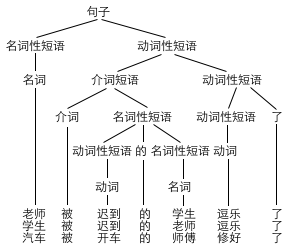
而分析句法结构的任务,则是已知一个句子从左到右各词的词性,要反过来求出一棵满足要求的“句法结构树”。这可以用 Earley parser 来实现。
这样看来,句法结构的问题似乎就已经完美的解决了。其实,我们还差得很远。生成语法有两个大问题。首先,句法结构正确的句子不见得都是好句子。 Chomsky 本人给出了一个经典的例子: Colorless green ideas sleep furiously 。形容词加形容词加名词加动词加副词,这是一个完全符合句法要求的序列,但随便拼凑会闹出很多笑话——什么叫做“无色的绿色的想法在狂暴地睡觉”?顺便插播个广告,如果你还挺喜欢这句话的意境的,欢迎去我以前做的 IdeaGenerator 玩玩。不过,如果我们不涉及句子的生成,只关心句子的结构分析,这个缺陷对我们来说影响似乎并不大。生成语法的第二个问题就比较麻烦了:从同一个词性序列出发,可能会构建出不同的句法结构树。比较下面两个例子:
老师 被 迟到 的 学生 逗乐 了
电话 被 窃听 的 房间 找到 了
它们都是“名词+介词+动词+的+名词+动词+了”,但它们的结构并不一样,前者是老师被逗乐了,“迟到”是修饰“学生”的,后者是房间找到了,“电话被窃听”是一起来修饰房间的。但是,纯粹运用前面的模型,我们无法区分出哪句话应该是哪个句法结构树。如何强化句法分析的模型和算法,让计算机构建出一棵正确的句法树,这成了一个大问题。
让我们来看一个更简单的例子吧。同样是“动词+形容词+名词”,我们有两种构建句法结构树的方案:
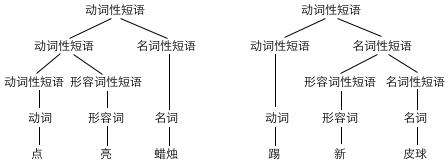
未经过汉语语法训练的朋友可能会问,“点亮蜡烛”和“踢新皮球”的句法结构真的不同吗?我们能证明,这里面真的存在不同。我们造一个句子“踢破皮球”,你会发现对于这个句子来说,两种句法结构都是成立的,于是出现了歧义:把皮球踢破了(结构和“点亮蜡烛”一致),或者是,踢一个破的皮球(结构和“踢新皮球”一致)。
但为什么“点亮蜡烛”只有一种理解方式呢?这是因为我们通常不会把“亮”字直接放在名词前做定语,我们一般不说“一根亮蜡烛”、“一颗亮星星”等等。为什么“踢新皮球”也只有一种理解方式呢?这是因为我们通常不会把“新”直接放在动词后面作补语,不会说“皮球踢新了”、“衣服洗新了”等等。但是“破”既能作定语又能作补语,于是“踢破皮球”就产生了两种不同的意思。如果我们把每个形容词能否作定语,能否作补语都记下来,然后在生成规则中添加限制条件,不就能完美解决这个问题了吗?
基于规则的句法分析器就是这么做的。汉语语言学家们已经列出了所有词的各种特征:
亮:词性 = 形容词,能作补语 = True ,能作定语 = False ⋯⋯
新:词性 = 形容词,能作补语 = False ,能作定语 = True ⋯⋯
⋯⋯
当然,每个动词也有一大堆属性:
点:词性 = 动词,能带宾语 = True ,能带补语 = True ⋯⋯
踢:词性 = 动词,能带宾语 = True ,能带补语 = True ⋯⋯
污染:词性 = 动词,能带宾语 = True ,能带补语 = False ⋯⋯
排队:词性 = 动词,能带宾语 = False ,能带补语 = False ⋯⋯
⋯⋯
名词也不例外:
蜡烛:词性 = 名词,能作主语 = True ,能作宾语 = True ,能受数量词修饰 = True ⋯⋯
皮球:词性 = 名词,能作主语 = True ,能作宾语 = True ,能受数量词修饰 = True ⋯⋯
⋯⋯
有人估计会觉得奇怪了:“能作主语”也是一个属性,莫非有些名词不能做主语?哈哈,这样的名词不但有,而且还真不少:剧毒、看头、地步、正轨、存亡⋯⋯这些词都不放在动词前面。难道有些名词不能做宾语吗?这样的词也有不少:享年、芳龄、心术、浑身、家丑⋯⋯这些词都不放在动词后面。这样说来,存在不受数量词修饰的词也就不奇怪了,事实上上面这些怪异的名词前面基本上都不能加数量词。
另外一个至关重要的就是,这些性质可以“向上传递”。比方说,我们规定,套用规则
名词性短语 → 形容词性短语+名词性短语
后,整个名词性短语能否作主语、能否作宾语、能否受数量词修饰,这将取决于它的第二个构成成分。通俗地讲就是,如果“皮球”能够作主语,那么“新皮球”也能够作主语。有了“词语知识库”,又确保了这些知识能够在更高层次得到保留,我们就能给语法生成规则添加限制条件了。例如,我们可以规定,套用规则
动词性短语 → 动词性短语+名词性短语
的前提条件就是,那个动词性短语的“能带宾语”属性为 True ,并且那个名词性短语“能作宾语”的属性为 True 。另外,我们规定
动词性短语 → 动词性短语+形容词性短语
必须满足动词性短语的“能带补语”属性为 True ,并且形容词性短语“能作补语”属性为 True 。这样便阻止了“踢新皮球”中的“踢”和“新”先结合起来,因为“新”不能作补语。
最后我们规定,套用规则
名词性短语 → 形容词性短语+名词性短语
时,形容词性短语必须要能作定语。这就避免了“点亮蜡烛”中的“亮”和“蜡烛”先组合起来,因为“亮”通常不作定语。这样,我们便解决了“动词+形容词+名词”的结构分析问题。
当然,这只是一个很简单的例子。在这里的问题 6 、 7 、 8 中你可以看到,一条语法生成规则往往有很多限制条件,这些限制条件不光是简单的“功能相符”和“前后一致”,有些复杂的限制条件甚至需要用 IF … THEN … 的方式来描述。你可以在这里看到,汉语中词与词之间还有各种怪异的区别特征,并且哪个词拥有哪些性质纯粹是知识库的问题,完全没有规律可循。一个实用的句法结构分析系统,往往拥有上百种属性标签。北京大学计算语言所编写了《现代汉语语法信息词典》,它里面包含了 579 种属性。我们的理想目标就是,找到汉语中每一种可能会影响句法结构的因素,并据此为词库里的每一个词打上标签;再列出汉语语法中的每一条生成规则,找到每一条生成规则的应用条件,以及应用这条规则之后,整个成分将会以怎样的方式继承哪些子成分的哪些属性,又会在什么样的情况下产生哪些新的属性。按照生成语言学的观点,计算机就应该能正确解析所有的汉语句子了。
那么,这样一来,计算机是否就已经能从句子中获取到理解语义需要的所有信息了呢?答案是否定的。还有这么一些句子,它从分词到词义到结构都没有两可的情况,但整个句子仍然有歧义。考虑这句话“鸡不吃了”,它有两种意思:鸡不吃东西了,或者我们不吃鸡了。但是,这种歧义并不是由分词或者词义或者结构导致的,两种意思所对应的语法结构完全相同,都是“鸡”加上“不吃了”。但为什么歧义仍然产生了呢?这是因为,在句法结构内部,还有更深层次的语义结构,两者并不相同。
汉语就是这么奇怪,位于主语位置上的事物既有可能是动作的发出者,也有可能是动作的承受者。“我吃完了”可以说,“苹果吃完了”也能讲。然而,“鸡”这个东西既能吃,也能被吃,歧义由此产生。
位于宾语位置上的事物也不一定就是动作的承受者,“来客人了”、“住了一个人”都是属于宾语反而是动作发出者的情况。记得某次数理逻辑课上老师感叹,汉语的谓词非常不规范,明明是太阳在晒我,为什么要说成是“我晒太阳”呢?事实上,汉语的动宾搭配范围极其广泛,还有很多更怪异的例子:“写字”是我们真正在写的东西,“写书”是写的结果,“写毛笔”是写的工具,“写楷体”是写的方式,“写地上”是写的场所,“写一只狗”,等等,什么叫做“写一只狗”啊?我们能说“写一只狗”吗?当然可以,这是写的内容嘛,“同学们这周作文写什么啊”,“我写一只狗”。大家可以想像,学中文的老外看了这个会是什么表情。虽然通过句法分析,我们能够判断出句子中的每样东西都和哪个动词相关联,但从语义层面上看这个关联是什么,我们还需要新的模型。
汉语语言学家把事物与动词的语义关系分为了 17 种,叫做 17 种“语义角色”,它们是施事、感事、当事、动力、受事、结果、系事、工具、材料、方式、内容、与事、对象、场所、目标、起点、时间。你可以看到,语义角色的划分非常详细。同样是动作的发出者,施事指的是真正意义上的发出动作,比如“他吃饭”中的“他”;感事则是指某种感知活动的经验者,比如“他知道这件事了”中的“他”;当事则是指性质状态的主体,比如“他病了”中的“他”;动力则是自然力量的发出者,比如“洪水淹没了村庄”中的“洪水”。语义角色的具体划分以及 17 这个数目是有争议的,不过不管怎样,这个模型本身能够非常贴切地回答“什么是语义”这个问题。
汉语有一种“投射理论”,即一个句子的结构是由这个句子中的谓语投射出来的。给定一个动词后,这个动词能够带多少个语义角色,这几个语义角色都是什么,基本上都已经确定了。因而,完整的句子所应有的结构实际上也就已经确定了。比如,说到“休息”这个动词,你就会觉得它缺少一个施事,而且也不缺别的了。我们只会说“老王休息”,不会说“老王休息手”或者“老王休息沙发”。因而我们认为,“休息”只有一个“论元”。它的“论元结构”是:
休息 <施事>
因此,一旦在句子中看到“休息”这个词,我们就需要在句内或者句外寻找“休息”所需要的施事。这个过程有一个很帅的名字,叫做“配价”。“休息”就是一个典型的“一价动词”。我们平时接触的比较多的则是二价动词。不过,它们具体的论元有可能不一样:
吃 <施事,受事>
去 <施事,目标>
淹没 <动力,受事>
三价动词也是有的,例如
送 <施事,受事,与事>
甚至还有零价动词,例如
下雨 <Ф>
下面我们要教计算机做的,就是怎样给动词配价。之前,我们已经给出了解析句法结构的方法,这样计算机便能判断出每个动词究竟在和哪些词发生关系。语义分析的实质,就是确定出它们具体是什么关系。因此,语义识别的问题,也就转化为了“语义角色标注”的问题。然而,语义角色出现的位置并不固定,施事也能出现在动词后面,受事也能出现在动词前面,怎样让计算机识别语义角色呢?在回答这个问题之前,我们不妨问问自己:我们是怎么知道,“我吃完了”中的“我”是“吃”的施事,“苹果吃完了”中的“苹果”是“吃”的受事的呢?大家肯定会说,废话,“我”当然只能是“吃”的施事,因为我显然不会“被吃”;“苹果”当然只能是“吃”的受事,因为苹果显然不能发出“吃”动作。也就是说,“吃”的两个论元都有语义类的要求。我们把“吃”的论元结构写得更详细一些:
吃 <施事[语义类:人|动物],受事[语义类:食物|药物]>
而“淹没”一词的论元结构则可以补充为:
淹没 <动力[语义类:自然事物],受事[语义类:建筑物|空间]>
所以,为了完成计算机自动标注语义角色的任务,我们需要人肉建立两个庞大的数据库:语义类词典和论元结构词典。这样的人肉工程早就已经做过了。北京语言大学 1990 年 5 月启动的“九〇五语义工程”就是人工构建的一棵规模相当大的语义树。它把词语分成了事物、运动、时空、属性四大类,其中事物类分为事类和物类,物类又分为具体物和抽象物,具体物则再分为生物和非生物,生物之下则分了人类、动物、植物、微生物、生物构件五类,非生物之下则分了天然物、人工物、遗弃物、几何图形和非生物构件五类,其中人工物之下又包括设施物、运载物、器具物、原材料、耗散物、信息物、钱财七类。整棵语义树有 414 个结点,其中叶子结点 309 个,深度最大的地方达到了 9 层。论元结构方面则有清华大学和人民大学共同完成的《现代汉语述语动词机器词典》,词典中包括了各种动词的拼音、释义、分类、论元数、论元的语义角色、论元的语义限制等语法和语义信息。
说到语义工程,不得不提到董振东先生的知网。这是一个综合了语义分类和语义关系的知识库,不但通过语义树反映了词与词的共性,还通过语义关系反映了每个词的个性。它不但能告诉你“医生”和“病人”都是人,还告诉了你“医生”可以对“病人”发出一个“医治”的动作。知网的理念和 WordNet 工程很相似,后者是 Princeton 在 1985 年就已经开始构建的英文单词语义关系词典,背后也是一个语义关系网的概念,词与词的关系涉及同义词、反义词、上下位词、整体与部分、子集与超集、材料与成品等等。如果你装了 Mathematica,你可以通过 WordData 函数获取到 WordNet 的数据。至于前面说的那几个中文知识库嘛,别问我,我也不知道上哪儿取去。
看到这里,想必大家会欢呼,啊,这下子,在中文信息处理领域,从语法到语义都已经漂亮的解决了吧。其实并没有。上面的论元语义角色的模型有很多问题。其中一个很容易想到的就是隐喻的问题,比如“信息淹没了我”、“悲伤淹没了我”。一旦出现动词的新用法,我们只能更新论元结构:
淹没 <动力[语义类:自然事物|抽象事物],受事[语义类:建筑物|空间|人类]>
但更麻烦的则是下面这些违背语义规则的情况。一个是否定句,比如“张三不可能吃思想”。一个是疑问句,比如“张三怎么可能吃思想”。更麻烦的就是超常现象。随便在新闻网站上一搜,你就会发现各种不符合语义规则的情形。我搜了一个“吃金属”,立即看到某新闻标题《法国一位老人以吃金属为生》。要想解决这些问题,需要给配价模型打上不少补丁。
然而,配价模型也仅仅解决了动词的语义问题。其他词呢?好在,我们也可以为名词发展一套类似的配价理论。我们通常认为“教师”是一个零价名词,而“老师”则是一个一价名词,因为说到“老师”时,我们通常会说“谁的老师”。“态度”则是一个二价的名词,因为我们通常要说“谁对谁的态度”才算完整。事实上,形容词也有配价,“优秀”就是一个一价形容词,“友好”则是一个二价形容词,原因也是类似的。配价理论还有很多更复杂的内容,这里我们就不再详说了。
但还有很多配价理论完全无法解决的问题。比如,语义有指向的问题。“砍光了”、“砍累了”、“砍钝了”、“砍快了”,都是动词后面跟形容词作补语,但实际意义各不相同。“砍光了”指的是“树砍光了”,“砍累了”指的是“人砍累了”,“砍钝了”指的是“斧子砍钝了”,“砍快了”指的是“砍砍快了”。看来,一个动词的每个论元不但有语义类的限制,还有“评价方式”的限制。
两个动词连用,也有语义关系的问题。“抓住不放”中,“抓住”和“不放”这两个动作构成一种反复的关系,抓住就等于不放。“说起来气人”中,“说起来”和“气人”这两个动作构成了一种条件关系,即每次发生了“说起来”这个事件后,都会产生“气人”这个结果。大家或许又会说,这两种情况真的有区别吗?是的,而且我能证明这一点。让我们造一个句子“留着没用”,你会发现它出现了歧义:既可以像“抓住不放”一样理解为反复关系,一直把它留着一直没有使用;又可以像“说起来气人”一样理解为条件关系,留着的话是不会有用的。因此,动词与动词连用确实会产生不同的语义关系,这需要另一套模型来处理。
虚词的语义更麻烦。别以为“了”就是表示完成,“这本书看了三天”表示这本书看完了,“这本书看了三天了”反而表示这本书没看完。“了”到底有多少个义项,现在也没有一个定论。副词也算虚词,副词的语义同样捉摸不定。比较“张三和李四结婚了”与“张三和李四都结婚了”,你会发现描述“都”字的语义没那么简单。
不过,在实际的产品应用中,前面所说的这些问题都不大。这篇文章中讲到的基本上都是基于规则的语言学处理方法。目前更实用的,则是对大规模真实语料的概率统计分析与机器学习算法,这条路子可以无视很多具体的语言学问题,并且效果也相当理想。最大熵模型和条件随机场都是目前非常常用的自然语言处理手段,感兴趣的朋友可以深入研究一下。但是,这些方法也有它们自己的缺点,就是它们的不可预测性。不管哪条路,似乎都离目标还有很远的一段距离。期待在未来的某一日,自然语言处理领域会迎来一套全新的语言模型,一举解决前面提到的所有难题。