在处理最优化问题时,我们常常通过分析导函数来寻找极值点,因此往往希望目标函数是可导的;但在很多实际问题中,目标函数里经常带有取最大值函数,它的存在将破坏函数的可导性。一个有趣的问题由此产生:能否设计一个平滑的二元函数 f(x,y) ,它的效果近似于 max(x,y) ,足以用来代替最大值函数?在设计这样的函数时,下面这些条件需要尽可能满足:
· 函数简洁而美观
· 可以调整函数的“平滑度”
· 可以很方便地扩展到多个变量
我在这里发现了一个非常漂亮的构造: ln(exp(x) + exp(y)) 。由于 x 和 y 都在指数位置上,因此它们的差距将会放得很大。比方说, 3 和 8 这两个数虽然相隔不远,但 e^3≈20.0855 , e^8≈2980.96 ,两个幂差了几个数量级。因此,把 e^3 加到 e^8 上,几乎不会改变 e^8 的大小。对 e^3+e^8 取对数的结果和直接对 e^8 取对数的结果相差不多。事实上, ln(exp(3) + exp(8))≈8.00672 ,非常逼近最大值函数的结果。
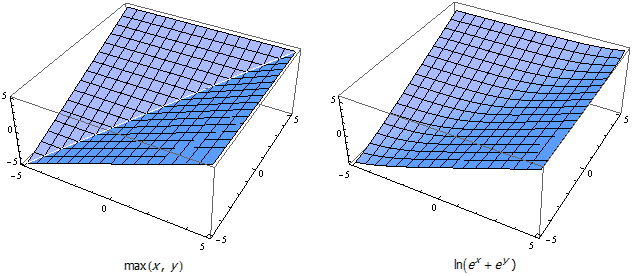
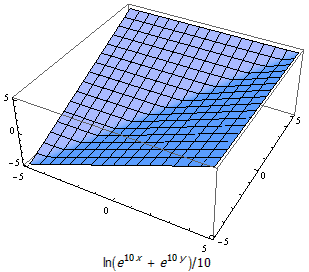
这个函数有很多好处。首先,它看上去非常漂亮,并且很容易参与到其它运算中。其次,它可以非常方便地扩展到 n 个变量的情况,即 ln(exp(x_1) + exp(x_2) + … + exp(x_n)) 。另外,这个函数的精确程度是可以控制的。显然,由于指数函数越到后面变化幅度越大,因此这个函数对尺度较大的变量来说会变得更加精确。如果把 3 和 8 变成 30 和 80 ,函数结果可以精确到小数点后 20 多位。因此,我们可以用一个系数 k 来调节变量的尺度,让 x 和 y 同时扩大 k 倍,最后结果再除以 k 。换句话说,把函数重新写成 ln(exp(k·x) + exp(k·y))/k , k 越大整个函数将越逼近最大值函数, k 越小函数也就变得越平滑。
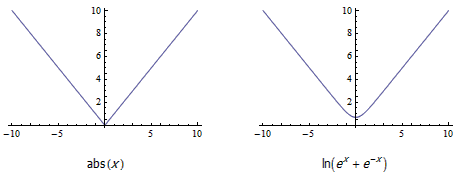
有了这个函数后,很多本身不可导的函数立即有了可导的近似函数。例如,绝对值函数 abs(x) 其实可以写作 max(x,-x) ,因此可以用可导函数 ln(exp(x) + exp(-x)) 近似代替:
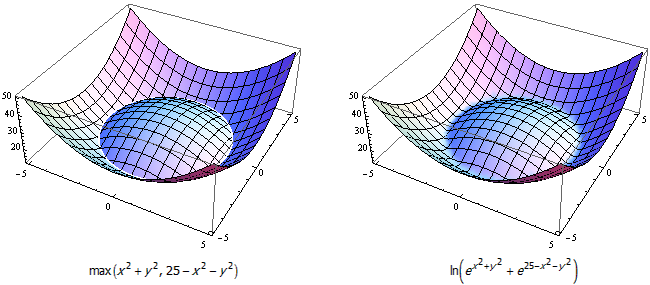
对于复合函数的情形,用 ln(exp(g(x,y)) + exp(h(x,y))) 代替 max(g(x,y), h(x,y)) 同样能带来很好的效果:
OMG… I love it!!
不错,赞一个。开始没明白“平滑”的意思,后来明白了。
善
写程序的话,用这个代替max函数处理整数变量会很好吗
终于有一篇能看懂的文章了
觉得此思想极其王道,顶之,@地板,我觉得这个还是没有必要的吧
好强大的构造,膜拜。
啊哈 新发现啊
Orz
看来我要试图拓展自己的订阅范围了,不能被E文吓到= =b
abs(0)的值和ln(exp(0)+exp(0))的距离有点远……
嗯,同上。
其实只是个探索嘛……要是地板同学还是用if或者三目运算符吧
膜拜牛淫。强势围观
这个牛逼
这个就是Lie group对黎曼几何的表述吧
好强!
哈?
看懂了,但是这个有什么用呢……
替M67牛回LS
没啥用
Blog本来就是要消遣一下嘛
Geek的消遣
第一段就是用处,楼上两个居然说没啥用……
后续的文章
http://www.johndcook.com/blog/2010/01/20/how-to-compute-the-soft-maximum/
说到了如何避免当x太大(比如1000)或者太小(比如-1000)时,exp(x)会返回无穷大或者0的情况。有兴趣的可以去看看。
地幔惊现onion
说实话我米看懂
这个近似太好了!!!唉他们是杂想到的喃,
talented!
嗯,我看懂了。
洗澡的时候灵光一现,再来看了一遍,果然懂了
不过当x,y非常接近的时候,误差似乎就比较大了。比如如果x=y=1那么误差就有ln2了。
@chipper
所以需要一个常数k.只要x!=y,即可用此法.
这个做聚类分析应该可以用上吧,大家有没有用这个函数做过聚类?
orz,虽然考试用不上,但确实太牛逼了
调整平滑度–类似脑筋急转弯感觉
这个实在是太帅了,多谢楼主分享美文^^
Max-Log approxiamtion?
我把程序改进了一下,填上了整数模式并且在默认情况下平滑度系数是自适应搜索的,并且基本上不会出现overflow情况.
function g=softmax(x,y,k,int)
%return a soft max result between x and y with the soft coeficient k
%error between softmax and max is less then ln2/k
%g=softmax(x,y,k,int)
%g=softmax(x,y)
%INPUT
%x,y:numbers to compare
%int:integer mode
%k:soft coeficient
%EXAMPLE
% x=2,y=5
%Running the program we get:
% ans =
%
% 5
%see also max
%written by wilson 12/12/2010
%E-mail:Yiwei_gu09@gmail.com
if nargin==2
int=0;
k=1/20;
while k<=10000
g=log(exp(k*x)+exp(k*y))/k;
if g==inf || g==-inf
break
end
k=k*2;
end
k=k/2;
g=log(exp(k*x)+exp(k*y))/k;
if g==inf || g==-inf
error(‘manually set the value to k where k is suggest to be either larger than 10000 or smaller than 1/20’)
end
end
if nargin==3
int=0;
end
g=log(exp(k*x)+exp(k*y))/k;
if int==1
g=round(g);
end
大家有没有用这个函数做过聚类?
Max(a,b)=(a+b+√((a-b)↑2))/2
Min(a,b)=(a+b-√((a-b)↑2))/2
今天发现了这个操作,这个就是softmax啊!
确实 ,softmax的分母就是用这个 soft vrsion 代替 max
原本归一化是 x_{i} / x_{max}, softmax 用上述技巧 平滑了 前面的归一化公式