很多问题并不完全符合二分的模型。最常见的一个情况估计应该是无穷长的有序队列中的二分查找问题。例如,前文所提到的求解x^x=a实际上就是这样的问题,这里x的取值范围可以是大于0的所有实数。当然,这里的x明显有一个上界,比如x明显要比a小。但是,如果有什么二分问题,它没有一个明确的上界呢?比如,我们再玩一次猜数游戏,我想一个数,然后告诉你你的猜测是大了还是小了。不同的是,我不告诉你这个数是在什么范围内选的,我想的数可以是任意一个正整数。那你该怎么办呢?最初的想法当然是,不断往大的猜,直到某个时候它超过了目标值为止;然后以它为上界,剩下的就可以看作有限多了。关键是,我们以什么样的跨度来枚举这个上界?首先必须肯定的是,这个上界枚举序列必须是发散的,否则会有数我们一辈子也猜不到;同时,线性增长的策略也是很傻的:跨度太小了你可能得到猴年才能找出上界,跨度太大了的话一来就确定了上界,但待考虑的队列也可能远远超过所需。一个比较灵活的想法是:按照1, 2, 4, 8, 16, …, 2^n的序列来猜测上界。这是一种“相对大小”的思想:既然连前面N个数都小了,我们也就不在乎那么一两个了,不妨直接再跳过N个数直接考察2N。这样的话,整个猜测过程仍然保持log(n)的复杂度,整个算法也更加美观一些。
假如你有一台时光机,可以让你到任意远的未来去,你打算怎么来使用它?或许你会说,先去100年后看看,生活一年之后再去200年后体验体验,然后再去300年后生活一年,再去400年后生活一年……其实,这种线性的时光旅行并不科学。当你已经跨越了数千年以后,相比之下100年的跨度已经不算遥远了,1000年后与1100年后的差异远远没有今天和100年以后的变化那样令人震撼。我说我和Stetson MM的思维如出一辙,那不是说着好玩的。一次MSN聊天时我们讨论到这个话题,两人同时想到了这样的时间旅行方式:先直接跳到1年后生活,再到2年后生活一段时间,再到4年后,再到8年后……用这种方式来体验未来,即使我在每一个时间点停留一年,我也能保证见到从我余生的感情生活到人类文明的各种不可思议的形态,甚至到文明的轮回与宇宙的毁灭等各种尺度下的牛B事。我的确能够看到充分远的未来,了解到足够宏大的文明史和宇宙史:假设我还能活80年,那么我可以看到2^80=1208925819614629174706176年内的种种,这么多年里估计就是宇宙热寂也该结束了。
折纸后的高度、在棋盘里放米、Hanoi塔与世界末日……无数火星的例子告诉我们,倍增的力量是异常强大的。如果你不信的话,下次来北京时请我喝酒,不妨这样来试试:先我喝一杯,你喝一口;然后我喝一杯,你喝两口;然后我喝一杯,你喝四口……看咱俩谁坚持的久。
倍增法有许多出乎意料的神奇应用。有兴趣的读者不妨去看一看Chan凸包算法,这是我所见过的倍增法最诡异的应用。
另一个不符合二分模型的相关问题是:如何寻找凸函数上的极大点?生活中的很多东西都是这样,大了也不好,小了也不好,不多不少的时候最好。我最喜欢举的例子是,粉笔短了不好写且用得快,粉笔长了又容易断;为了贯彻拿MM打比方的精神,这里可以再举一些例子来说明这一情况的普遍性:陪MM出去玩的次数多了很快会腻,陪MM次数少了又会疏远;把握火候贯彻“半糖主义”方针是非常重要的。事实上,从硬盘缓存的大小到初期农民的个数,从每学期的学分到论文的长度,生活中几乎所有东西都是这样,就连饭量和睡眠时间也是。这些例子说穿了就是一个单峰函数,我们需要用尽可能少的试验次数快速找到极大点。永远不要以为决策者们面对的都是高中数学考卷上的“每涨10块钱就会少100个消费者”一类的屁话,这些屁话都是用来编二次函数题目的。现实生活中企业做决策时,样点实验、不断取舍、逐步逼近最优点仍然是最实在最有效的手段。考虑到我们今天的话题,我们首先要做的是,想一个可以让规模层层递减的方法。这个办法貌似不错:从函数中选择两个点x、y(无妨假设x<y),如果f(x)<f(y),那么去掉所有比x还小的部分;反之若f(x)>f(y),那么y点的右边都可以抛弃掉。不管这两个点是在极大点的同侧还是异侧,抛弃较小值那一侧都是正确的。另外,如果不巧f(x)=f(y),这说明极大值一定在它们之间,去掉哪一边都是可以的。
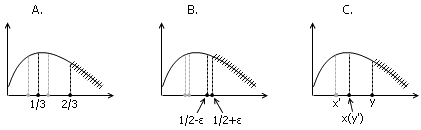
问题的关键就是,每一次我们的x和y取在哪里最合适?或许有人会说,既然有两个点,那就对称地取在三等分处吧。这样的话,每次问题的规模都降低到原来的2/3。当然,更好的办法是把两个点都取到中点附近,相互之间的距离充分小;这虽然不那么美观,但每次的规模都将变为原先的1/2+ε,效率上说显然更好一些。最聪明的做法是,把x和y两点取在一对既不远也不近的合适位置上,使得其中一个点(比如y)被去掉后,x点所在的位置正好可以作为下一个测试点(于是每一轮新的实验就只需要取一个点了)。这种“循环利用”旧测试点的做法将更加节省资源。为了保证这一过程可以永远进行下去,我们希望让x在y点去掉后的那一段上的位置与y点原先在整段上所处的位置比例相同,用算式写出来就是y/L=x/y,即(L-x)/L = x/(L-x),解出来x=(1±√5)L/2。神奇!黄金分割竟然出现在了这样一个意想不到的场合中!这就是所谓的“优选法”:不断在两个黄金分割点处进行测试,抛弃较次的测试点;由于黄金分割点的性质,另一个点仍然处于余下部分的黄金比例处,因此只需再对该小段的另一黄金分割点进行测试即可继续如此递归地操作下去。
二分的应用范围还很广。这里我们再举四个简单的例子,它们是二分法的各种极其特殊的用法。首先,我们来看看交互式问答题中的一个奇妙的二分。黑箱子中有一个竞赛图(任两点之间都有一条单向边)。询问两个顶点,返回它们之间的边的方向。请用尽量少的询问次数找出一条经过全部n个顶点的路径。
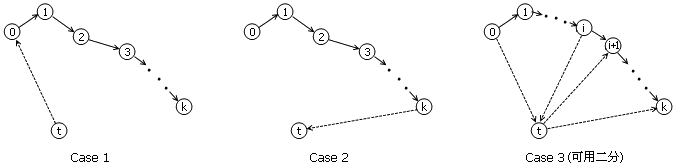
竞赛图有一个神奇的性质:经过所有顶点的路是一定存在的。换句话说,如果n个人之间两两进行比赛,假设比赛没有平局;那么我们一定能够给这n个人排出一个顺序,使得第一个人打败了第二个人,第二个人打败了第三个人,一直到倒数第二个人打败了最末一个人。这个证明是构造性的。从任意一条边出发,我们可以不断扩展出越来越长的链。假设现在我们已经有了一个长度为k的链,它们的节点分别是P_0, P_1, …, P_k。现在我们想把节点P_t加进来,使得这条链的长度达到k+1。注意到,如果有边P_t → P_0或者P_k → P_t,那就直接完事儿了。否则的话,我们必须要找出链中的一个P_i,使得P_i → P_t并且P_t → P_(i+1),然后将P_t插到P_i和P_(i+1)中间。这样的P_i是一定存在的,因为此时P_0到P_t的边是正向的,但到了P_k时从链到P_t的边却变成逆向的了,这说明中间至少有从正向边变成逆向边这一步。换句话说,给你一个长度为k的01串,首位为0,末尾为1,那中间至少出现了一次子串“01”。
按照这种方法做,最坏情况下我们需要询问O(n^2)条边。这相当于把整个图都给你了。有更好的办法吗?有!我们可以用二分法寻找P_i,从而只需要O(nlogn)次询问即可得到答案。具体地说,每次需要寻找那个P_i时,我们二分P_i的位置:如果有P_i→P_t,则P_t一定能插入到P_i后面的部分;反之如果P_t→P_i,则需要寻找的目标节点一定在它前面。用01串来解释似乎更清楚一些:由于每个首位为0末位为1的子串都包含至少一个“01”,于是我们看中间那一位数。如果它是“0”,即可抛弃前面那一段;如果它是“1”,则后面那一段就可以不管它了。
接下来,让我们看一看二分法在两个有序数组中的应用。在多个有序数组中查找指定的数不好玩,真正好玩的是在多个有序数组中查找指定序数的数。给你两个有序数组,如何快速找出第k小的数?合并两个有序数组将导致线性的复杂度,这里还有更好的算法吗?不啰嗦了,我直接给出答案:分别取两个数组正中间的那个数a和b,不妨设a≥b。两个数组被划分为四段,分别记作A1、A2、B1和B2。如果A1的长度与B1的长度加起来还没有k大,那所求数绝对不可能在B1里面(任选B1中的一个数,比它小的只有A1和B1各自的一部分数,数目远不到k);反之如果len(A1)+len(B1)≥k,那么所求元素必然不在A2中(因为A1和B1里的所有数都比A2里的数小,而它们就已经有k个了)。对于两种情况,我们都可以将某个数组的长度减半,从而得到log级别的算法。
1 2 3 6 7 8 14 *16* 18 19 20 23 27 28 33
|<--- A1 --->| a |<------- A2 ------->|
4 5 9 10 11 *12* 14 17 22 24 29
|<-- B1 -->| b |<---- B2 ---->|
在竞赛题目中,大家见过最多的当属二分加贪心检测了。当然,偶尔也会遇到二分加最短路、二分加匹配、二分加网络流、二分加动态规划之类的题目。但是,大家有想过二分加二分的题目吗?前不久,我就见过这么一道“两次二分”的题目:给你n个数,这n个数两两的差值将产生n(n-1)/2个数。试求这n(n-1)/2个数的中位数。算法:二分答案加二分检测。先二分这个中位数,然后数一数比该数小的有多少,比该数大的又有多少,以确定这个“中位数”是取大了还是取小了。为了判断有多少个数比选定的中位数小,我们需要再一次使用二分:对于每一个固定的数A_i,二分A_j的位置,看A_i-A_j比中位数大还是小(j=1..i-1,假设数列已经有序)。假设n个数中的最大值为q,则算法的复杂度为O(n*log(n)*log(q))。
有时候,二分的作用甚至根本就不是为了减小时间复杂度。某天在阅微堂看到一个非常有趣的题目。假设有两台计算机,每台计算机上都存了一个长度为n的字符串。两台计算机之间的数据传输是非常昂贵的。因此,我们希望用最少的数据传输量来确定,哪台计算机上存储的字符串的字典序更大。
答案:一个基于概率的二分算法。两台机器各自算出前半段字符串的md5值,然后机器A把它的md5值传过来和机器B比。把比较结果传回去。若两个md5值不等,表明第一个不同之处一定在这里面发生,此时即可抛弃后面一半;若两个md5值相等则说明不同的地方一定在后面,前面这一半即可舍去。(补充一句,这里的“一定”并不是真的一定,md5判重是有概率因素的。)
二分这个话题太有趣了,好玩的东西说也说不完。欢迎大家在下面留言,分享你所见过的最有趣、最奇妙、最不可思议的二分。