2006 年,我在博客(当时还是 MSN Space)上发了 《什么是 P 问题、NP 问题和 NPC 问题》 一文。这是我高二搞信息学竞赛时随手写的一些东西,是我的博客中最早的文章之一。今天偶然发现,这篇现在看了恨不得重写一遍的“科普”竟仍然有比较大的阅读量。时间过得很快。《星际争霸》(StarCraft)出了续作,德国队 7 比 1 大胜东道主巴西,《学徒》(The Apprentice)里的那个家伙当了总统,非典之后竟然出了更大的疫情。现在已经是 2022 年了。这 16 年的时间里,我读了大学,出了书,娶了老婆,养了娃。如果现在的我写一篇同样话题的科普文章,我会写成什么样呢?正好,我的新书《神机妙算:一本关于算法的闲书》中有一些相关的内容。我从书里的不同章节中摘选了一些片段,整理加工了一下,弄出了下面这篇文章,或许能回答刚才的问题吧。
复杂度
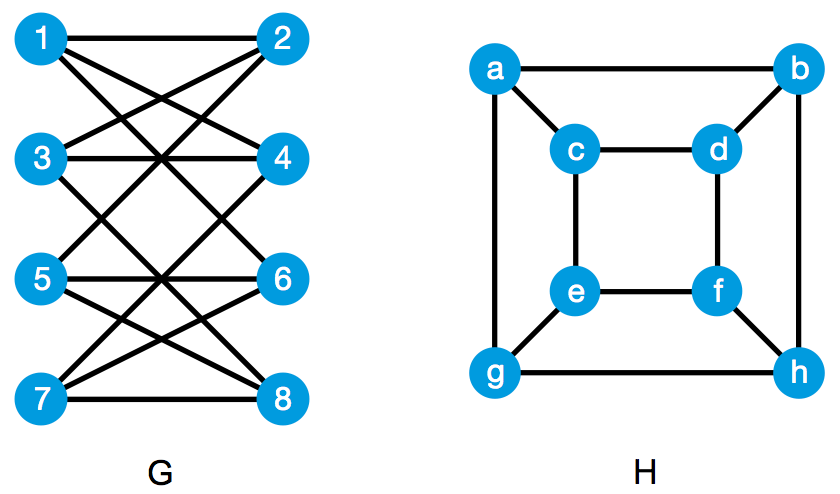
趣题:怎样向别人证明两个图不同构?
若干个顶点(vertex)以及某些顶点对之间的边(edge)就构成了一个图(graph)。如果图 G 和图 H 的顶点数相同,并且它们的顶点之间存在着某种对应关系,使得图 G 中的两个顶点之间有边,当且仅当图 H 中的两个对应顶点之间有边,我们就说图 G 和图 H 是同构的(isomorphism)。直观地说,两个图是同构的,意思就是它们本质上是同一个图,虽然具体的画法可能不一样。下面的两个图就是同构的。其中一种顶点对应关系是: 1 – a, 2 – c, 3 – d, 4 – b, 5 – e, 6 – g, 7 – h, 8 – f 。
目前,人们还没有找到任何高效的算法,能迅速判断出两个图是否同构。在普通计算机上,判断两个图是否同构,这需要花费大量的时间。因此,人们经常以图的同构为例,来解释复杂度理论和现代密码学中的诸多概念。
假设你家里的计算机十分强大,能很快判断出两个图是否同构,还能在两个图确实同构的情况下,给出一种顶点对应关系。但你的同桌家里的计算机却非常弱,没法做什么大型运算。课堂上,老师向全班展示了两个很复杂的图,不妨把它们叫作图 G 和图 H 。老师布置了一个特别的选做题:判断出这两个图是否同构。每个同学都可以提交答案,答案里只需要写“是”或者“不是”即可。按时提交答案并答对者,期末考试会获得 5 分加分;按时提交答案但答错了的,期末考试成绩将会倒扣 30 分;不参与此活动的同学,期末考试既不加分也不扣分。显然,每个同学都不敢随意提交答案,除非百分之百地能保证自己获得的答案是正确的。回到家后,借助家里的超级计算机,你很快判断出了这两个图是同构的。你给你的同桌发送了信息:“我已经算出来了,这两个图是同构的。”但是,你的同桌却回复说:“你不会是骗我的吧?”你打算怎样说服他,这两个图确实是同构的呢?
通信复杂度问题:利用特殊机器判断公共元素的存在性
某个导师要和 A 、 B 两名学生玩一个游戏。导师会把 A 、 B 两名学生分别放进两间小黑屋里,每间屋子里都有一台电脑,这两台电脑之间只有一条通信线路。然后,导师会想一个正整数 n (可能会非常非常大),把它的值告诉这两名学生;再构造出集合 {1, 2, …, n} 的两个子集,分别交给这两名学生。于是,每个人都知道了 n 的值和 {1, 2, …, n} 的一个子集。两人需要合作确定出,他们手中的集合是否包含公共的元素。他们之间交流信息的唯一途径就是那条通信线路,但他们能够使用的流量是有限的。具体能够使用多少 bit 的流量,这可以由他们自己决定,但必须在游戏开始之前(也就是 n 的值确定之前)就定好并告诉导师。
和其他类似的问题一样,在游戏开始之前,两人可以商量一个对策。不过,这一回,两人商量了很久,始终无法找到一个必胜的对策。就在两人快放弃的时候,他们突然发现,两人的通信线路上存在一个“漏洞”:两人都可以不计流量地访问一台特殊的第三方机器,我们不妨把它叫做机器 O 。不过,机器 O 只能做一件事情:从 A 那儿读取一个 1 到 n 的排列,从 B 那儿读取一个 1 到 n 的排列,然后计算出这两个排列复合之后是否恰好含有一个循环,并将计算结果分别告知 A 和 B 。然后,机器 O 就会自动关机,再也不能访问了。也就是说,A 和 B 只能使用机器 O 一次。注意, A 、 B 两人是无法看到对方传给机器 O 的数据的,另外机器 O 只能用于处理 1 到 n 之间的排列,不能处理其他大小的排列。
趣题:如何在数据库中秘密地查询隐私数据
日常生活中经常会出现这样的场景:你想在数据库上查询某个东西,但却不希望留下线索,让别人知道你查询了什么。比方说,投资人可能会在数据库上查询某支股票的信息,但却不希望任何人知道他感兴趣的股票究竟是哪一支。看上去,似乎唯一的办法就是把整个数据库全部拷回家。然而,这些数据往往都拥有非常庞大的体积,全部拷走通常都是很不现实的;另外,考虑到数据内容的隐私性和数据本身的宝贵价值,数据的持有者通常也不允许其他人把整个数据全盘拷走。不过,随着分布式数据库的广泛应用,上面的难题有了一个两全其美的好办法:假设有两个内容完全相同的数据库,投资人可以先在第一个数据库上执行一个不会透露目的的查询,再在另一个数据库上执行另一个不会透露目的的查询,两次查询结合起来便能推出想要的结果。只要没有人刻意去收集并且对比两个数据库的查询记录,那么谁也不会知道投资人真正想要查询的是什么。在这个背景下,我们有了下面这个有趣的问题。
服务器随机产生了一个 {1, 2, …, 100} 的子集 S ,并且同时发送给了 A 和 B 两名前台工作人员。 A 、 B 两名前台都接受其他人的提问,但为了保护数据,两个人都只能用“是”或者“否”来回答问题,并且都不允许同一个人重复提问。你非常关心某个数 n 是否在这个子集里。其实,你本来可以直接问 A 和 B 中的任何一个人“数字 n 是否在集合 S 里”,但是这样一来,对方就知道了你想要查询的是什么。为此,你可以向 A 和 B 各问一个问题(结合两人的回答便能推出集合 S 里是否包含数字 n ),但却不能让 A 和 B 当中的任何一个人知道你查询的是哪个数(我们假设 A 、 B 两人不会串通起来,把他们各自收到的问题联系在一起)。事实上,你需要保证 A 和 B 两人都不能从你的问题中获取到任何信息,也就是说,对于 A 和 B 当中的任何一个人来说,各种问题出现的概率不会随着 n 值的改变而改变。再换句话说,如果 n 的值变了,那么 A 和 B 各自将会听到的问题应该拥有和原来相同的概率分布。
通信复杂度问题:确定双方手中所有数的中位数
通信复杂度(communication complexity)主要研究这么一类问题: A 持有数据 x , B 持有数据 y ,他们想要合作计算某个关于 x 和 y 的二元函数值 f(x, y) ,那么在渐近意义下,两人至少需要传输多少 bit 的数据。最近着迷于通信复杂度,看到了几个与通信复杂度有关的问题,和大家分享一下。下面就是其中之一。
A 、 B 的手中各有一个 {1, 2, …, n} 的子集。两人想知道,如果把他们手中的数全都放在一块儿,那么这些数(可能会有重复的数)的中位数是多少。然而, A 、 B 两人远隔千里,他们之间通信的成本非常高。因此,他们想在通信线路上传输尽可能少的信息,使得最终两人都知道中位数的值。在这里,为了简便起见,我们直接定义 m 个数的中位数是第 ⌈ m / 2 ⌉ 小的数,因而如果 m = 2k ,那么中位数就应该直接取第 k 小的数。
其中一种最笨的方法是, A 把手中的所有数全部发给 B 。由于发送一个不超过 n 的正整数最多会用到 log(n) 个 bit ,而 A 手里的数最多有 O(n) 个,因此 A 传给 B 的信息量就是 O(n · logn) 。于是, B 就得到了足够多的信息,可以直接计算中位数了,算好后再把结果告诉 A ,此时又要耗费 log(n) 个 bit (但它并不会成为通信量的瓶颈)。因此,在这种方案中,总的通信复杂度就是 O(n · logn) 。事实上,传送一个 {1, 2, …, n} 的子集只需要一个 n 位 01 串就够了,因而我们可以把通信复杂度降低到 O(n) 个 bit 。
利用下面的办法,我们可以实现 O(logn · logn) 的通信复杂度。首先, A 、 B 分别告诉对方自己手中有多少个数,这一共会耗费 O(logn) 个 bit 。接下来,两人在区间 [1, n] 上进行二分查找。假设到了某一步,中位数被限定在了区间 [i, j] 里,那么 A 就计算出 k = (i + j) / 2 ,数一数自己手中有多少个数比 k 小,然后告诉 B ,由 B 再来数数自己这边又有多少个比 k 小的数,从而判断出 k 作为中位数来说是偏大了还是偏小了,并把判断出来的结果返回给 A 。根据情况,区间 [i, j] 将被更新为 [i, k] 或者 [k, j] ,两人在新的区间上继续二分下去。整个算法将会持续 O(logn) 轮,每一轮都会传输 O(logn) 的数据,因此总的通信复杂度是 O(logn · logn) 。
另一方面,通信复杂度至少是 Ω(logn) 的。这是因为,如果规定 A 和 B 最多只能交流 k 个 bit ,那么整个交流历史最多就只有 k 次分岔的机会,到最后最多只能产生 2k 个不同的分支;但事实上中位数有可能是 1 到 n 中的任何一个,共有 n 种不同的可能,因此 2k 必须大于等于 n 。这说明 k 必须大于等于 log2(n) ,也就是说两个人总会有必须要交流 log2(n) 个 bit 才行的时候。
一个有意思的问题自然而然地诞生了:我们所得的上界和下界仍然有差距。究竟是刚才的算法还不够经济,还是刚才证明的结论还不够强呢?
还想说明一点的是,两个人商量算法的过程,或者其中一个人把算法告诉另一个人的过程,这可以不算进通信复杂度里。事实上,把它们算进通信复杂度里也没关系,因为它们反正都是 O(1) 的。